
Related project: Adhan Caster Pro — a self-hosted, zero-latency Islamic prayer automation system running on a Raspberry Pi 4.
TL;DR
I took a production home-automation system — a Raspberry Pi 4 that calculates Islamic prayer times, casts a live dashboard to a Google Nest Hub, and pauses an Android TV during prayers — and gave it a brain that runs entirely on the device. Using Gemma 3 (1B) served by Ollama, the system now answers natural-language questions ("how long until Asr?"), writes human-readable explanations when a cast fails, generates a daily dashboard greeting, and keeps an advisory feedback loop that suggests its own tuning.
No cloud. No API keys. No data leaving the house. And — this was the hard constraint — the AI is never allowed near the real-time cast path, so the Adhan still fires on time to the millisecond.
Background: what the Adhan Caster already did
Before any AI, the Adhan Caster was already a mature, high-uptime system:
- ▪Local prayer-time calculation from a pre-baked annual schedule (no runtime cloud lookups).
- ▪Casting a high-definition dashboard + Adhan audio to a Google Nest Hub via
chromecast-api, with an adaptive cast lead that self-tunes off the rolling p75 of observed cast-to-playing latency. - ▪Android TV control over ADB — and not a blind toggle: it inspects
dumpsys audio/dumpsys media_session, sends a pause, re-checks, and falls back to mute if a live stream ignored the pause. - ▪Self-healing discovery: mDNS rediscovery, a 6-hour cast cache with stale-streak bias, persisted window-retries that survive restarts, and an ADB keep-alive state machine.
- ▪Three PM2 processes —
adhan-caster,adb-keeper,auto-updater— with metrics synced to Firebase and a public dashboard mirror.
The point is important: this code works and is tested. So the design rule for the AI layer was simple — cover gaps and add capability without modifying a single line of the proven cast/pause/discovery/recovery logic.
Why edge AI, and why Gemma 3 1B + Ollama
The obvious move would be to call a hosted LLM. I deliberately didn't.
- ▪Privacy. This is a device in my home that knows my routine. The reasoning layer should never phone home.
- ▪Resilience. The whole project's value proposition is that it keeps working when the internet doesn't. A cloud-dependent AI would betray that.
- ▪Cost & latency. Zero per-token cost, and for local queries no WAN round-trip.
- ▪It's a Pi 4. A 4 GB ARM board, CPU-only. That rules out anything large.
Gemma 3 1B is the sweet spot: a genuinely capable instruction-tuned model whose quantized weights are ~815 MB — small enough to load on the Pi, large enough to follow structured instructions and produce clean JSON. Ollama wraps it in a local HTTP server on 127.0.0.1:11434, so a Node.js app talks to it with a plain fetch/axios POST. No Python runtime, no GPU, no orchestration framework.
I pinned resource limits with a custom Modelfile:
FROM gemma3:1b
PARAMETER num_ctx 2048 # cap context memory for a 4GB board
PARAMETER num_thread 2 # leave CPU headroom for the cast pipeline
PARAMETER temperature 0.1 # deterministic, factual answers
PARAMETER top_p 0.7
ollama create gemma3-constrained -f ./Modelfile
Architecture: an intelligence layer, bolted on the side
The cardinal rule — off the real-time cast path — drove the entire design. Inference on a Pi 4 CPU takes anywhere from ~3 s (warm) to ~30–60 s (cold load), while the cast must fire roughly 2 seconds before prayer time. Putting an LLM call anywhere in that window would be reckless. So the AI lives entirely in its own modules and is forbidden from running inside a prayer's critical window.
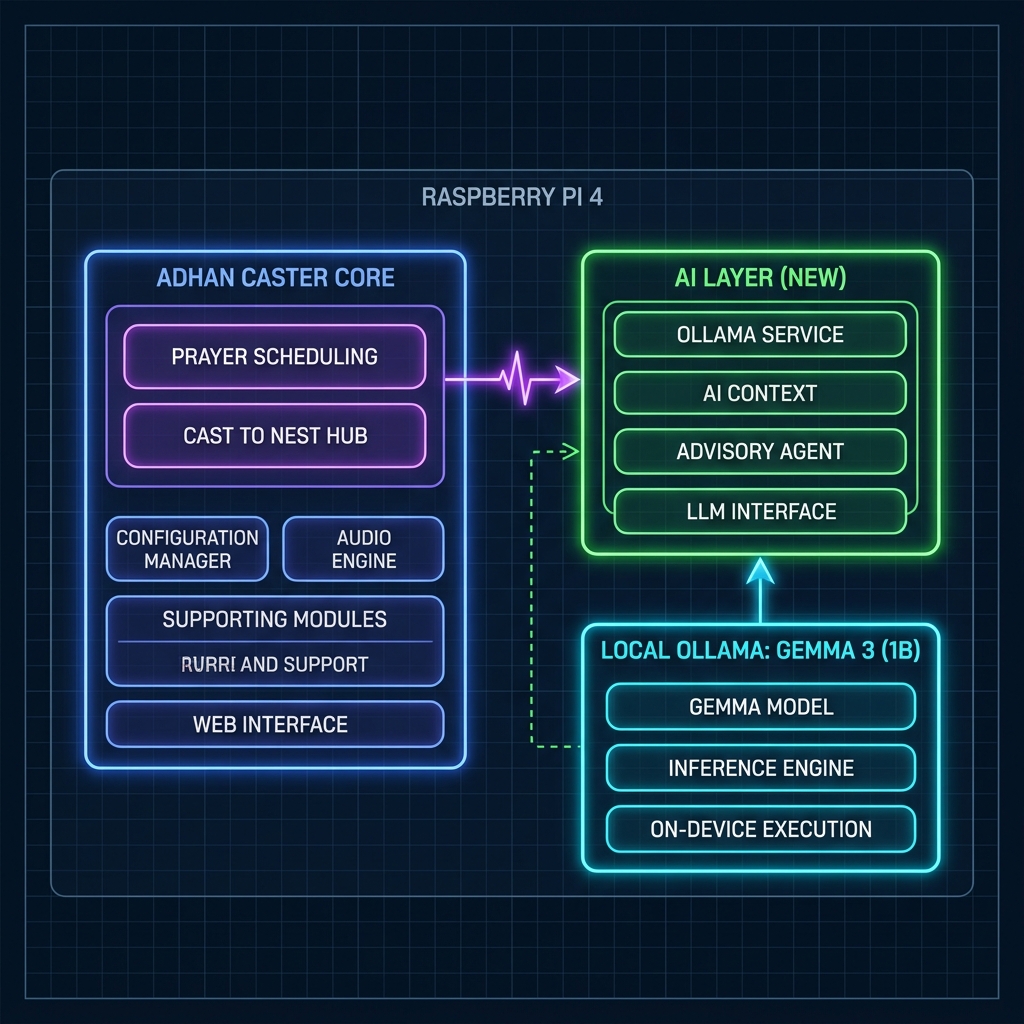
Three new Node.js modules, all CommonJS, all reusing the project's existing conventions (axios, luxon, console logging):
- ▪
OllamaService— the only thing that talks to Ollama. Single-flight (a Pi 4 can't run two inferences at once), hard timeouts, a JSON-fence-stripping parser, a health check, a quiet-window guard, a circuit breaker + watchdog, and a model warm-up. - ▪
aiContext— builds a compact, pre-computed plain-text snapshot of system state (next prayer, per-prayer countdowns, today's playback results). The model reads facts; it never does arithmetic. - ▪
AdvisoryAgent— owns the off-path features (failure diagnosis, daily blurb, tuning advisory) and the persistent memory buffer.
Exposed through the existing Express server (port 3001): POST /api/ask, GET /api/ask/health, GET /api/blurb, GET /api/advisory.
Primary features
1. Natural-language assistant (/api/ask)
Ask plain-English questions about the system and get a grounded answer:
curl -s -X POST http://<pi-ip>:3001/api/ask \
-H 'Content-Type: application/json' \
-d '{"question":"how long until Asr?"}'
# {"answer":"Asr begins at 16:56, in 11h 49m.","source":"gemma","latencyMs":3120}
The key trick: a 1B model is poor at clock arithmetic, so I don't ask it to compute. aiContext does the math in code and hands the model an explicit, unambiguous list:
Note: every clock time below is a START time — when that prayer/Adhan BEGINS.
Time until each prayer (already computed — use these exact values):
Dhuhr starts 13:05 → in 8h 2m; Asr starts 16:56 → in 11h 49m; ...
Today's playback: 2 played, 0 recovered, 0 failed, 0 pending (Fajr=PLAYED, Dhuhr=PLAYED).
The model's job is reduced to selecting and phrasing the right fact. If Ollama is slow or down, the endpoint falls back to a deterministic, code-computed answer so it never hard-fails.
2. Self-diagnosing failures
When a cast fails, the failure is queued and — later, in a quiet window — Gemma turns the raw event into a human-readable diagnosis:
"Cast handshake timed out; the Nest Hub was likely asleep or its IP changed on the local network."
This runs after the critical path and recovery are completely done. It never blocks, delays, or alters recovery — if the model is busy, the field simply stays empty.
3. Daily dashboard blurb
Once a day, in a quiet window, the system generates a short contextual greeting that the dashboard displays — e.g. "Welcome, seeker; today's Dhuhr prayer begins at 13:05, a time of reflection and blessings." Cached per day, with graceful fallback.
4. Advisory tuning loop (in-context "learning")
True reinforcement learning — updating model weights with reward functions — is not feasible on a Pi 4; there's no headroom for backpropagation on a billion-parameter model. What is feasible is an in-context feedback loop: a daily micro-agent reads the playback history, writes observations and tuning suggestions to a persistent memory buffer (ai-memory.json), and gets better-informed over time as that buffer grows.
Crucially, it is advisory only. It might suggest "consider raising PRAYER_CAST_LEAD_MS," but it never auto-applies anything, and it never touches the live p75 cast-lead controller that already self-tunes. A human reviews and decides.
5. The dashboard chat box
A small assistant card on the operations dashboard, with the round-trip time shown under each answer.

Note — currently HTTP, not HTTPS. The chat box is served over plain HTTP directly from the Raspberry Pi on the local network:
http://<pi-ip>:3001/dashboard.html. It is not yet exposed over HTTPS. On the LAN this is fine; for outside-the-home access I tunnel to the Pi over a VPN (Tailscale/WireGuard) rather than opening a port. The public GitHub Pages mirror of the dashboard intentionally cannot reach the private Pi (different origin, and a browser would block an HTTPS page calling an HTTP endpoint anyway), so the chat box only appears when the page is loaded directly from the Pi. A future iteration will front the Pi with an HTTPS reverse proxy / Tailscale Funnel.
6. Production-grade resilience
Because this runs unattended on real hardware, the wrapper is defensive by default — see the next section.
Chat box implementation
Backend (/api/ask)
app.post('/api/ask', async (req, res) => {
const startedAt = Date.now();
const question = String(req.body?.question || '').trim();
// ... validation ...
const context = aiContext.buildStatusContext(annualSchedulePath, CONFIG.timezone, playbackLogger);
if (!(await ollama.isAvailable(1500))) {
return res.json({ answer: deterministicAnswer(), source: 'fallback', latencyMs: Date.now() - startedAt });
}
const sys =
'You are the assistant for a home Adhan caster. Answer in 1-3 short sentences using ONLY the ' +
'system status below. To answer how long until a prayer, read that prayer\'s value verbatim from ' +
'the "Time until each prayer" line — never reuse the next-prayer figure for a different prayer, and ' +
'never compute times yourself. Every clock time is a START time — phrase answers as "starts/begins".';
const answer = await ollama.ask(sys, `SYSTEM STATUS:\n${context}\n\nQUESTION: ${question}`);
res.json(answer
? { answer, source: 'gemma', latencyMs: Date.now() - startedAt }
: { answer: deterministicAnswer(), source: 'fallback', latencyMs: Date.now() - startedAt });
});
Frontend (health-gated, origin-agnostic)
The chat UI only reveals itself if it can reach a live Ollama, and it shows you exactly how long the answer took:
// Reveal the box only when the Pi's AI is reachable from where the page loaded.
const r = await fetch(ASK_BASE + '/api/ask/health');
if ((await r.json()).available) showChatBox();
// On send: measure round-trip and display it.
const t0 = performance.now();
const res = await fetch(ASK_BASE + '/api/ask', { method: 'POST', /* ... */ });
const j = await res.json();
const roundTrip = ((performance.now() - t0) / 1000).toFixed(1);
answerEl.textContent = `${j.answer}\n⏱ answered in ${roundTrip}s (server ${(j.latencyMs/1000).toFixed(1)}s)`;
ASK_BASE defaults to same-origin (works when the page is served by the Pi) and can be overridden via a ?api= query param or localStorage for VPN access — with a documented hook left for a future Google Assistant route so the Nest Hub could one day answer by voice.
Engineering for a 4GB Pi: the resilience patterns
This is the part I'm most proud of, and the part that makes "LLM on a Pi" actually survivable in production.
Quiet-window guard. Every background AI job checks isQuiet() before running. The model is forbidden inside T-5min … T+8min of any prayer. If the schedule can't be read, it fails safe and holds off. This is what guarantees the AI never competes with a cast for CPU or RAM.
Single-flight. All inference serializes through one promise chain — the Pi can't run two at once, and queuing beats thrashing.
Circuit breaker + watchdog. Consecutive failures trip the breaker (CLOSED → OPEN), after which calls fail fast for a cooldown before a HALF_OPEN probe. If it trips, a watchdog can issue a restart of the Ollama service. The breaker means a wedged daemon degrades gracefully instead of hanging every request.
Warm-up + keep-alive. The first inference after a cold start can take 30–60 s while 815 MB loads into RAM. A boot-time warm-up (and Ollama's keep_alive) keeps the model resident so real queries land on the ~3 s warm path.
Graceful degradation everywhere. Ollama down? /api/ask returns a computed answer. Diagnosis can't run? The field stays empty. The blurb is missing? The dashboard shows nothing extra. Nothing the AI does can break the core system.
This held up in the real world: during one deploy the model timed out twice on a cold start — and the Asr cast that fired minutes later ran flawlessly, completely unaffected. That's the design working as intended.
Benefits analysis
| Dimension | Before (rules / cloud) | After (local Gemma 3) |
|---|---|---|
| Privacy | Any cloud AI = data leaves home | 100% on-device; nothing transmitted |
| Offline resilience | Cloud AI fails with the WAN | Works fully offline |
| Cost | Per-token / subscription | Zero marginal cost |
| UX | Rigid endpoints (/status) | Ask anything in plain English |
| Observability | Raw error codes in logs | Human-readable failure diagnoses |
| Adaptation | Static thresholds | Advisory tuning loop with memory |
| Latency (local) | n/a | ~3 s warm, deterministic fallback otherwise |
| Safety | n/a | Strictly off the real-time cast path |
Limitations & honest tradeoffs
- ▪Cold-start latency. After eviction, the first query can take 30–60 s on a 4 GB board. The dashboard surfaces this with the
⏱ answered in …line so it's never a mystery. - ▪Memory pressure. Pinning the model holds ~1–1.5 GB resident. On 4 GB, that competes with the cast pipeline, so warm-up is gated away from prayer windows and
keep_aliveis a dial, not a given. - ▪No real RL. Adaptation is in-context only; there's no on-device fine-tuning.
- ▪1B reasoning ceiling. The model is great at selecting and phrasing grounded facts, poor at open-ended math — which is exactly why the heavy lifting (countdowns, status) is pre-computed in code.
- ▪HTTP-only today. As noted above, the assistant is LAN-HTTP for now; HTTPS/remote is a roadmap item.
What's next
- ▪HTTPS + secure remote via a reverse proxy or Tailscale Funnel, so the chat works from the public dashboard too.
- ▪Voice on the Nest Hub through a Google Assistant route hitting
/api/ask(the hook is already stubbed). - ▪Dynamic dashboard generation — letting the model propose contextual visual themes for the cast, off-path and cached.
Closing
The interesting result here isn't "an LLM runs on a Raspberry Pi" — it's that a 1-billion-parameter model can be embedded into a real, latency-critical, production system as a genuinely useful layer without compromising the thing that already worked. The discipline — off the critical path, quiet-window gating, single-flight, circuit breaking, graceful fallback, and doing arithmetic in code instead of in the model — is what turns a fun demo into something I trust running unattended in my home.
Edge AI doesn't have to mean a flagship NPU and a cloud fallback. Sometimes it's an 815 MB model, a 4 GB board, and a lot of care about where the intelligence is allowed to run.
Appendix: quick reference
Install & constrain the model
curl -fsSL https://ollama.com/install.sh | sh
ollama pull gemma3:1b
ollama create gemma3-constrained -f ./Modelfile # see Modelfile above
Endpoints (served from the Pi on port 3001)
| Method | Path | Purpose |
|---|---|---|
| POST | /api/ask | Natural-language status query |
| GET | /api/ask/health | Is the local model reachable? |
| GET | /api/blurb | Today's cached dashboard greeting |
| GET | /api/advisory | Latest advisory-only tuning notes |
Stack: Raspberry Pi 4 (4 GB) · Node.js · Express · Ollama · Gemma 3 (1B) · PM2 · chromecast-api · ADB · Firebase (metrics).
Written by Bilal Ahamad
Technical QA Lead & AI-Driven Engineer